Part1 内容介绍
本次活动是一项专注于Deepfake技术鉴别的学习与竞赛活动,旨在提高参与者对Deepfake技术及其潜在危害的认识,并培养他们开发和应用鉴别模型的能力。Deepfake技术通过人工智能生成高度逼真的伪造图像、视频和音频,对社会的多个方面带来了挑战。本次活动响应这一挑战,通过技术学习和竞赛,推动AI向善的发展。
- 深入了解Deepfake原理,以及它们对社会的潜在影响。
- 获取深度学习模型的开发和优化经验。
- 掌握各类数据特征提取和数据增强方法。
Part2 活动安排
- 免费学习活动,不会收取任何费用。
- 请各位同学添加下面微信,并回复【deepfake竞赛学习】,即可参与。
Part3 积分说明和奖励
为了激励各位同学完成的学习任务,将学习任务根据难度进行划分,并根据是否完成进行评分难度高中低的任务分别分数为3、2和1。在完成学习后(本次活动,截止6月1),将按照积分顺序进行评选 Top3 的学习者。
Top1/2/3的学习者将获得以下奖励:
- 300、200、100元
- Coggle 竞赛专访机会
历史活动打卡链接,可以参考如下格式:
- https://blog.csdn.net/weixin_42551154/article/details/125474519
- https://blog.csdn.net/weixin_42551154/article/details/125481695
Part4 Deepfake图像与视频检测
背景介绍
Deepfake是一种使用人工智能技术生成的伪造媒体,特别是视频和音频,它们看起来或听起来非常真实,但实际上是由计算机生成的。这种技术通常涉及到深度学习算法,特别是生成对抗网络(GANs),它们能够学习真实数据的特征,并生成新的、逼真的数据。

Deepfake技术虽然在多个领域展现出其创新潜力,但其滥用也带来了一系列严重的危害。在政治领域,Deepfake可能被用来制造假新闻或操纵舆论,影响选举结果和政治稳定。经济上,它可能破坏企业形象,引发市场恐慌,甚至操纵股市。法律体系也面临挑战,因为伪造的证据可能误导司法判断。此外,深度伪造技术还可能加剧身份盗窃的风险,成为恐怖分子的新工具,煽动暴力和社会动荡,威胁国家安全。
为了应对这些挑战,本次活动旨在通过技术手段提高社会对Deepfake内容的鉴别能力。
- 模型开发:将使用深度学习框架(如TensorFlow或PyTorch)开发鉴别模型。
- 实战演练:将有机会在实际数据上测试和优化他们的模型。
- 参加 外滩大会·全球Deepfake攻防挑战赛,推动AI向善的技术。
学习打卡
| 任务名称 | 难度 |
|---|---|
| 任务1:了解Deepfake的任务定义、数据生成过程 | 低 |
| 任务2:下载活动的数据集,了解、读取数据集 | 低 |
| 任务3:构建CNN模型完成图像赛道鉴别任务 | 中 |
| 任务4:尝试进阶CNN模型,以及现在Deepfake前沿方法 | 高 |
| 任务5:尝试不同的数据增强方法 | 中 |
| 任务6:读取音视频赛道的数据集 | 高 |
| 任务7:提取音频特征、视频特征与关键帧等特征 | 中 |
| 任务8:尝试多模态分类方法 | 高 |
任务一:了解Deepfake的任务定义、数据生成过程
- 目标:理解Deepfake鉴别的核心任务和挑战。
- 步骤:
- 阅读有关Deepfake技术的基础资料。
- 学习Deepfake数据的生成方法,包括使用的工具和流程。
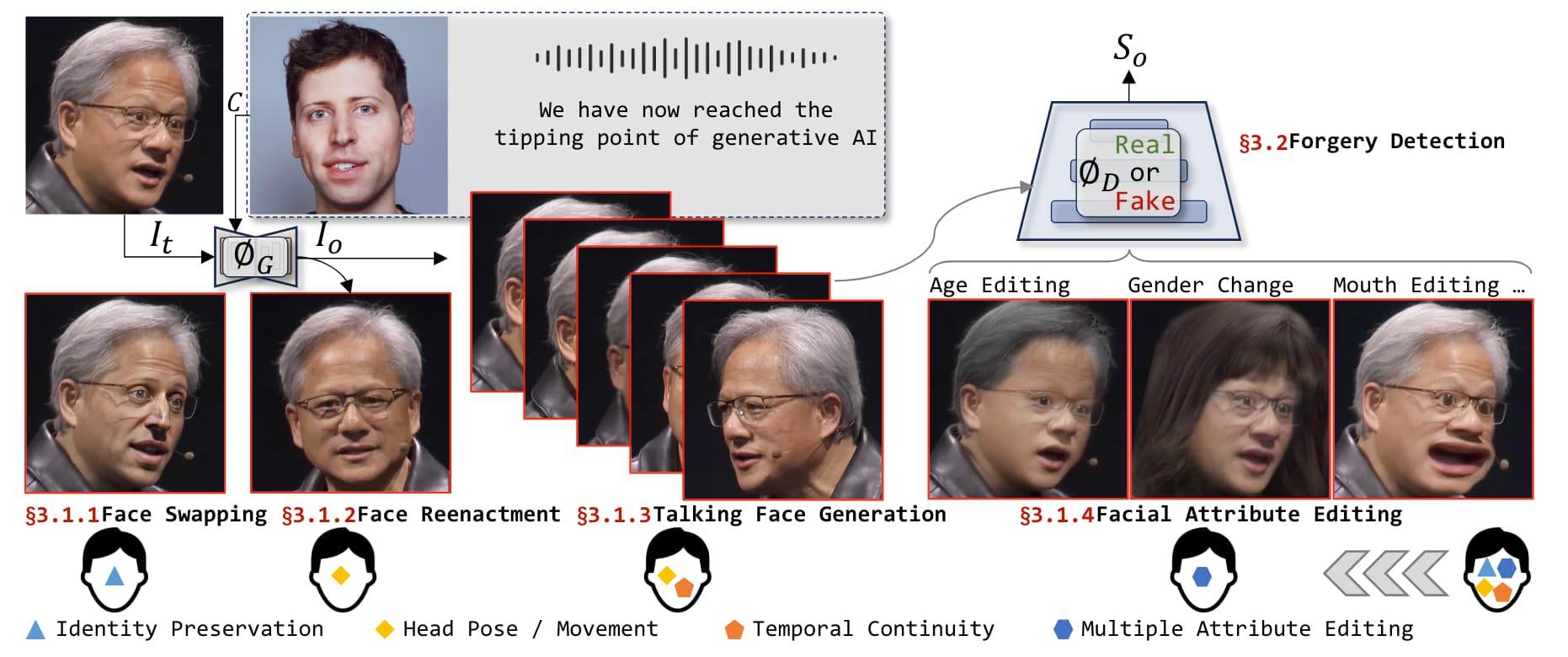
深度伪造技术通常可以分为四个主流研究方向:1)面部交换专注于在两个人的图像之间执行身份交换;2)面部重演强调转移源运动和姿态;3)说话面部生成专注于在角色生成中实现口型与文本内容的自然匹配;4)面部属性编辑旨在修改目标图像的特定面部属性。相关基础技术的发展已经从单一的前向GAN模型转变为具有更高质量生成能力的多步骤扩散模型,并且生成的内容也从单帧图像逐渐过渡到时间视频建模。
任务二:下载活动的数据集,了解、读取数据集
- 目标:获取并熟悉用于训练和测试鉴别模型的数据集。
- 步骤:
- 下载提供的数据集。
- 探索数据集的结构和内容。
- 学习如何使用适当的工具读取数据集。
赛题主页:ATEC前沿科技探索社区
- 图像赛题:Inclusion・The Global Multimedia Deepfake Detection | Kaggle
- 数据集为图片,原始数据集大小为30GB,样例数据2GB
- 音视频赛题:Inclusion・The Global Multimedia Deepfake Detection | Kaggle
- 数据集为图片,原始数据集大小为100GB,样例数据1GB
任务三:构建CNN模型完成图像鉴别任务
- 目标:使用卷积神经网络(CNN)模型鉴别图像是否为Deepfake。
- 步骤:
- 设计基本的CNN架构。
- 训练模型以区分真实和伪造的人脸图像。
- 调整模型参数,优化性能。
- 视觉赛题baseline:Deepfake-FFDI-图像赛题 baseline | Kaggle
- 音视频赛题baseline:Deepfake-FFDV-图像赛题 baseline | Kaggle
任务四:尝试进阶CNN模型和前沿方法
- 目标:探索更高级的CNN模型和当前Deepfake鉴别领域的前沿技术。
- 步骤:
- 研究和实现更复杂的CNN架构。
- 了解并尝试最新的Deepfake鉴别技术。
任务五:尝试不同的数据增强方法
- 目标:通过数据增强提高模型的泛化能力。
- 步骤:
- 学习不同的数据增强技术。
- 实施数据增强并评估其对模型性能的影响。
任务六:读取音视频赛道的数据集并完成鉴别任务
- 目标:使用音视频数据集鉴别Deepfake视频。
- 步骤:
- 读取和理解音视频数据集。
- 开发模型以鉴别视频是否为Deepfake,并输出概率。
任务七:提取音频特征、视频特征与关键帧等特征
- 目标:从音视频中提取有助于鉴别的关键特征。
- 步骤:
- 学习音频和视频特征提取技术。
- 提取并分析关键帧和其他相关特征。
任务八:尝试多模态分类方法
- 目标:结合图像、音频和视频特征,使用多模态方法进行Deepfake鉴别。
- 步骤:
- 研究多模态学习理论和方法。
- 实现一个多模态分类模型,结合不同模态的特征。
任务九:分析往期Deepfake鉴别竞赛中优胜方法
- 目标: 从成功案例中提取有价值的技术和策略,以优化自己的模型和解决方案。
- 步骤:
- 学习优胜者使用的技术,包括但不限于深度学习模型、数据增强方法、正则化技术等。
- 将学到的知识和策略应用到自己的模型开发和优化过程中。