Part1 内容介绍
随着人工智能技术的迅猛发展,特别是在自然语言处理(NLP)领域,机器理解人类语言的能力得到了显著提升。问答系统作为NLP技术的一个重要应用,旨在使机器能够理解用户的问题并提供准确的答案。然而,随着问答数据量的激增,如何高效地组织和管理这些数据,以更好地服务于问答系统,成为了一个亟待解决的问题。
在这样的背景下,问答意图聚类挑战赛应运而生,旨在通过聚类算法的设计与应用,将具有相同或相似意图的问题进行有效分组,从而提高问答系统的检索效率和用户体验。在本次学习中我们将学习:
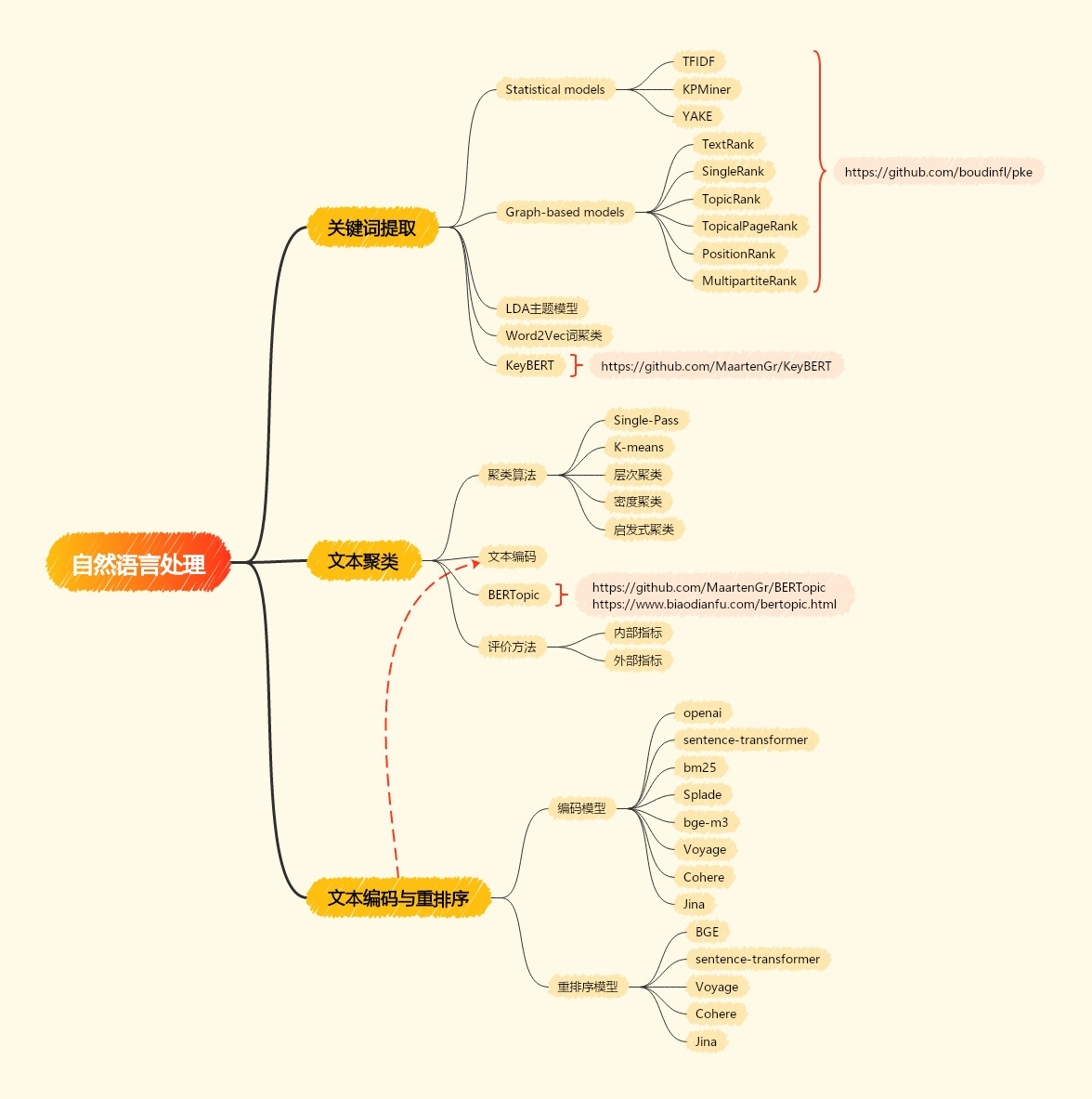
- 文本关键词提取方法
- 文本编码方法(相似度 与 重排序)
- 文本聚类方法
内容在线地址(持续更新):Coggle 30 Days of ML(24 年 8 月):文本问答聚类
在线评分地址:2024 iFLYTEK A.I.开发者大赛-讯飞开放平台
Part2 活动安排
- 免费学习活动,不会收取任何费用。
- 请各位同学添加下面微信,并回复【竞赛学习】,即可参与。
Part3 积分说明和奖励
为了激励各位同学完成的学习任务,将学习任务根据难度进行划分,并根据是否完成进行评分难度高中低的任务分别分数为3、2和1。在完成学习后(本次活动,截止9月1),将按照积分顺序进行评选 Top3 的学习者。
Top1的学习者将获得以下奖励:
- 天池便携音响
- Coggle 竞赛专访机会
Top2-3的学习者将获得以下奖励:
- Coggle 周边福利
- Coggle 竞赛专访机会
历史活动打卡链接,可以参考如下格式:
- https://blog.csdn.net/weixin_42551154/article/details/125474519
- https://blog.csdn.net/weixin_42551154/article/details/125481695
Part4 意图识别
背景介绍
本次活动是开发一个文本聚类模型,利用NLP技术(如文本分类模型),初步识别问题中的意图。也可以考虑使用深度学习模型生成的特征向量作为聚类的基础。
学习打卡
| 任务名称 | 难度/分值 |
|---|---|
| 文本处理基本任务 | 低 |
| 关键词提取技术 | 低 |
| 对比不同关键词提取方法 | 低 |
| 学习并应用m3e编码模型 | 低 |
| 学习并应用bge编码模型 | 低 |
| 学习并应用bge-m3编码模型 | 低 |
| 学习并应用qwen编码模型 | 低 |
| 学习使用重排序模型 | 低 |
| 学习不同的聚类算法(如K-means、DBSCAN等) | 低 |
| 掌握选择合适的聚类个数 | 低 |
| 应用聚类实现社区发现 | 低 |
1. 数据说明
训练集为一批没有带任何标签的用户提问,需要参赛选手从文本中提取提取特征并完成提问的聚类。最终需要对训练集的每个提问划分为聚类编号,并完成提交。
import pandas as pd
train = pd.read_csv('train.csv', sep='\t')
2. 评估指标
Rand Index 是一个简单的指标,用于衡量两个聚类结果之间的相似度。它通过计算样本对在两个不同的聚类结果中的一致性来实现。具体来说,对于每一对样本(i, j),如果它们在预测聚类(clustering)和真实聚类(ground truth)中都在同一聚类中,或者都不在同一聚类中,那么这对样本被认为是一致的。
尽管 Rand Index 是一个有用的度量,但它受到随机标签分配的影响,这意味着即使随机分配标签,也可能得到一个非零的 RI 值。为了解决这个问题,Adjusted Rand Index(ARI)被引入,它对 RI 进行了调整,以消除随机性的影响。
评价标准采用adjusted_rand_score指标,最高分为1。
from sklearn.metrics.cluster import adjusted_rand_score
adjusted_rand_score([0, 0, 1, 1], [0, 0, 1, 1])
思路1:bge + 文本聚类
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import pandas as pd
import numpy as np
import jieba
from tqdm import tqdm
import matplotlib.pyplot as plt
from sentence_transformers import SentenceTransformer
train = pd.read_csv('train.csv', sep='\t')
sentences_1 = ["样例数据-1", "样例数据-2"]
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
embeddings_1 = model.encode(train['title'].values, normalize_embeddings=True, show_progress_bar=True)
from sklearn.cluster import MiniBatchKMeans
km = MiniBatchKMeans(n_clusters=2000, verbose=0, max_iter=2000)
km.fit(embeddings_1)
train['topic'] = km.labels_
思路2:IDF 提取文本关键词
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=None, tokenizer=jieba.lcut).fit(train['title'])
word2idf = {x:y for x,y in zip(tfidf.get_feature_names_out(), tfidf.idf_)}
keywords = []
for title in train['title'].values:
# 分词
words = jieba.lcut(title)
# idf 信息量越大
longest_word = words[np.argmax([len(x) for x in words])]
words = [w for w in words if w in word2idf and len(w) > 1]
wordsidf = [word2idf[w] for w in words]
if len(wordsidf) == 0:
keyword = longest_word
else:
keyword = words[np.argmax(wordsidf)]
keywords.append(keyword)
train['keyword'] = keywords
train['topic'] = pd.factorize(train['keyword'])[0]
train[['qid', 'topic']].to_csv('submit.csv', index=None) # 0.13858861256080277